Editorial Note: One of the best parts of working on the Magenta project is getting to interact with the awesome community of artists and coders. Today, we’re very happy to have a guest blog post by one of those community members, Parag Mital, who has implemented a fast sampler for NSynth to make it easier for everyone to generate their own sounds with the model.
Introduction
NSynth is, in my opinion, one of the most exciting developments in audio synthesis since granular and concatenative synthesis. It is one of the only neural networks capable of learning and directly generating raw audio samples. Since the release of WaveNet in 2016, Google Brain’s Magenta and DeepMind have gone on to explore what’s possible with this model in the musical domain. They’ve built an enormous dataset of musical notes and also released a model trained on all of this data. That means you can encode your own audio using their model, and then use the encoding to produce fun and bizarre new explorations of sound.
Since NSynth is such a large model, naively generating audio would take a few minutes per sample, making it pretty much a nonstarter for creative exploration. Luckily, there is plenty of knowledge floating out there about how to make the WaveNet decoder faster1. As part of development for my course on Creative Applications of Deep Learning, I spent a few days implementing a faster sampler in NSynth, submitted a pull request to the Magenta folks, and it’s now part of the official repo. The whole team was incredibly supportive and guided me through the entire process, offering a ton of feedback. I’d highly encourage you to reach out via GitHub or the Magenta Google Group with any questions if you are interested in contributing to the project.
If you are interested in learning more about NSynth, WaveNet, or Deep Learning in general, I highly recommend that you join our growing community of students on Kadenze. We cover everything from the basics, to Magenta, NSynth, and plenty more, including some interviews with members of Magenta.
Encoding and Decoding your own sounds
Everything I show here is also included in the Jupyter Notebook located in the Magenta demos repo. Have a look there for more details on how these sounds were created.
Resynthesis
First, I explored resynthesizing sounds: simply encoding and decoding them without changing the encodings. Here’s an example of what an encoding looks like using NSynth’s pretrained model. This example shows a drum beat. You can see that the encoding seems to follow the overall pattern of the audio signal.
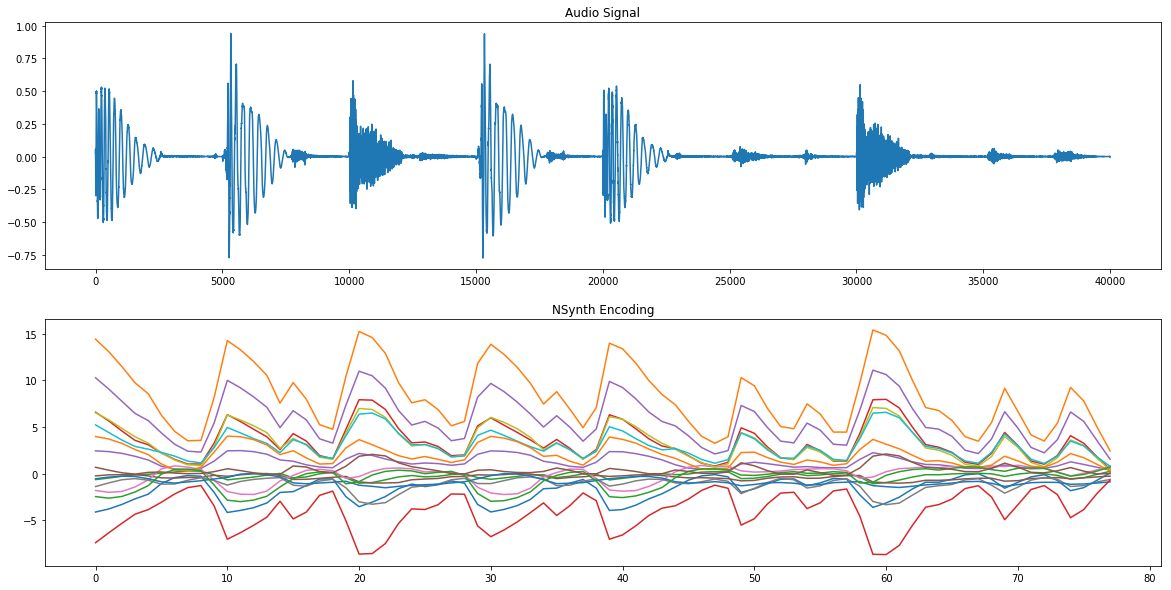
I then tried decoding this directly. This lets me hear the bias built into the model before exploring other manipulations, and can produce some really interesting results by itself. I found a few samples on http://freesound.org2 and generated these overnight. You can either use the command line tool nsynth_generate (see the README for more info), or, in the Jupyter Notebook, I also show how you can save embeddings and generate audio directly in python using the new fast generation module. Here are some example sounds I tried resynthesizing using NSynth:
Original:
Resynthesis:
Notice how much character these have! They are really weird. They are certainly not perfect reconstructions, as they are very different than the training data, but that is what makes them so interesting and fun to explore. Also, remember that NSynth was trained to use 8-bit mu-law 16kHz audio, so there is naturally a gritty lo-fi quality to the sound.
Timestretching
Next, I explored a fairly simple manipulation of the embedding space of NSynth by stretching it in time. The idea here is to perform a fairly established technique in audio synthesis called timestretching. If you were to try the same thing naively on the raw audio signal, you’d get a pitch shift. So making an audio signal longer would also reduce its pitch, and that might be undesirable. But what if you want to keep it the same length? There are plenty of other techniques out there like granular time stretching. But I found NSynth can also perform time stretching even though it was never designed to do so, simply by scaling its embeddings. What you do is take the encoding, so a 125 x 16 dimension matrix for a 4 second sample, and you stretch it like an image in any direction. Then you can synthesize the stretched embeddings.
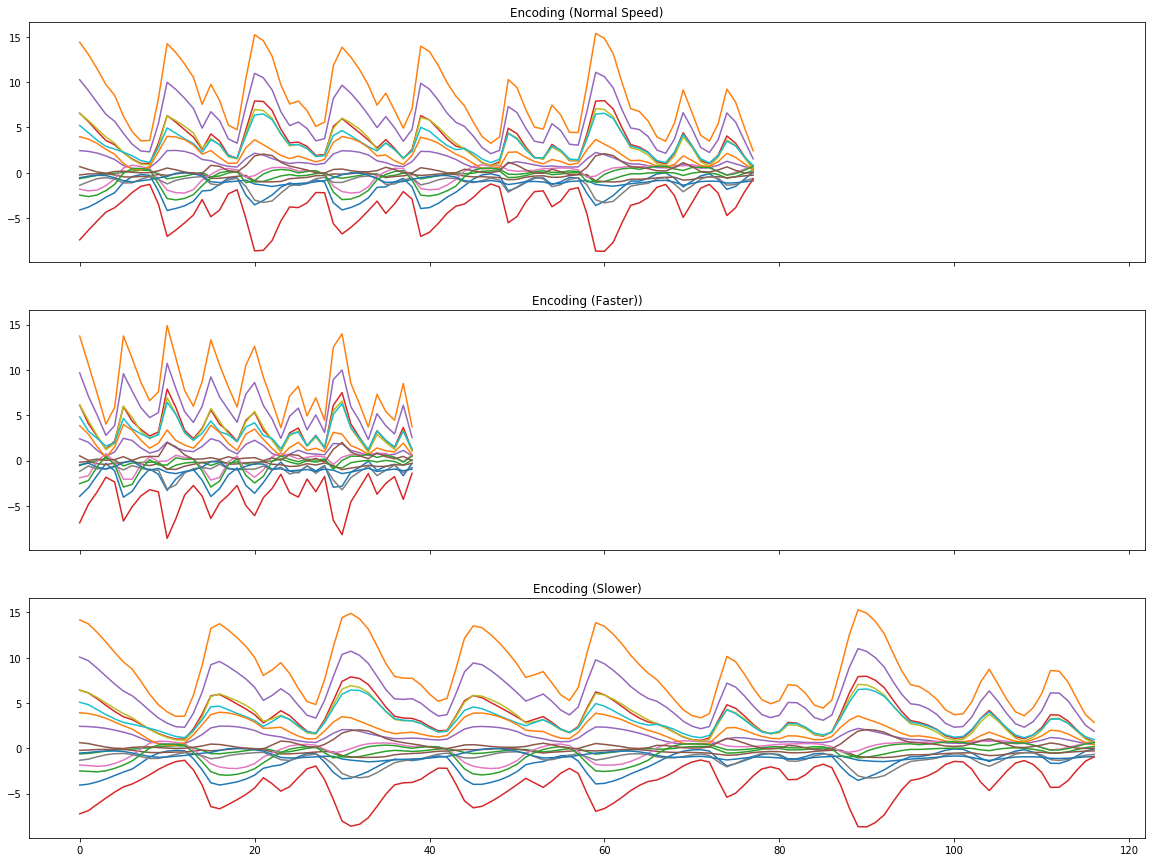
Here’s the original reconstruction:
And now twice as fast, by compressing it to half its length:
And here it is at 1.5 times as long in duration by stretching the embeddings matrix:
This is really the magical part of working with a neural audio synthesis technique. Much like word2vec’s linear representation of a verbal semantic space, NSynth’s encoding should similarly have a good representation of its dataset in its embedding. It would be great to see the community explore things like t-SNE visualizations, vector-based arithmetic of embeddings, and further manipulations of the embedding space that produce interesting results on the synthesized sound.
Interpolation
There are a few ways we could think about combining sounds. Magenta’s release of an NSynth instrument inside Ableton Live already demonstrates a really powerful way of interpolating between many different instrument sounds used in the training of NSynth. Also their collaboration with Google Creative Labs shows how to interpolate between any two sounds using NSynth.
Now we can explore interpolations of our own sounds! In the Jupyter Notebook, I show an example of mixing the breakbeat and the cello from above by simply averaging their embeddings together. This is unlike adding the two signals together in Ableton or simply hearing both sounds at the same time. Instead, we’re averaging the representation of their timbres, tonality, change over time, and resulting audio signal. This is way more powerful than a simple averaging.
Here’s the result of averaging the embeddings and resynthesizing them:
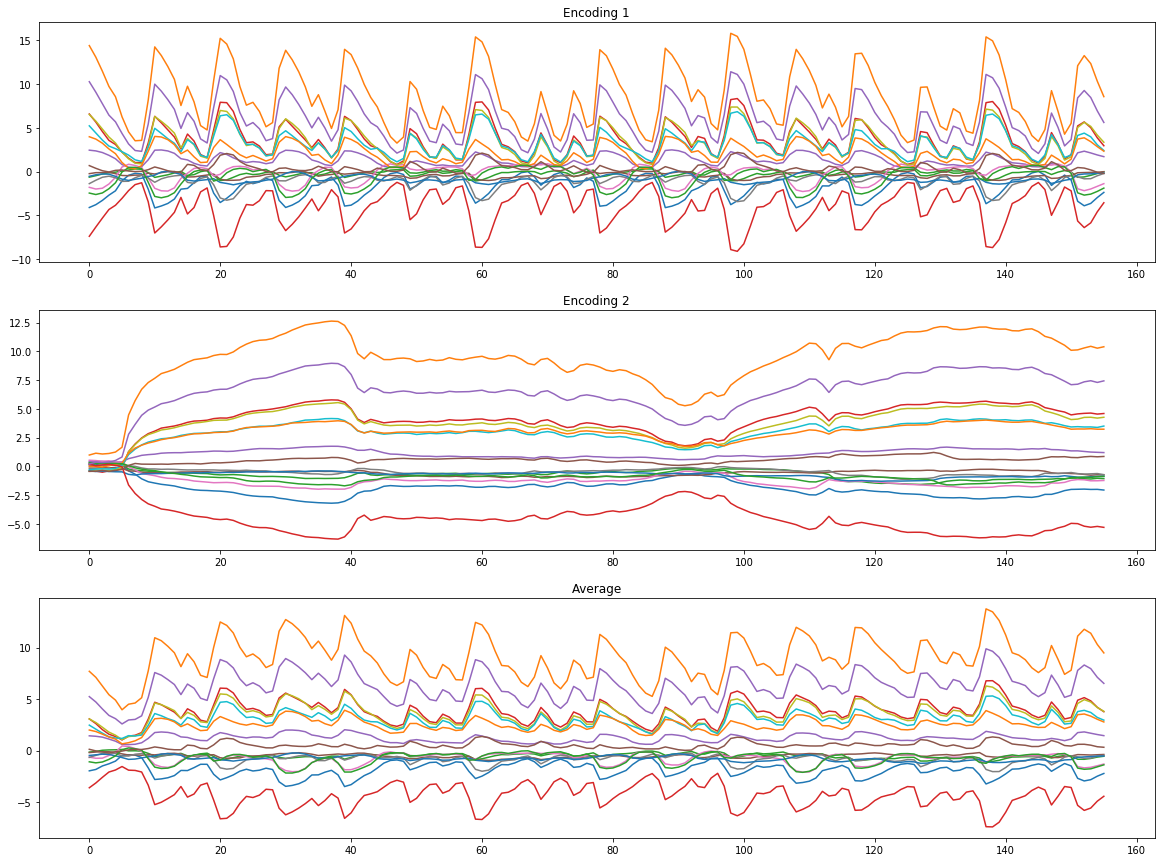
And here’s the result of crossfading the embeddings and resynthesizing them:
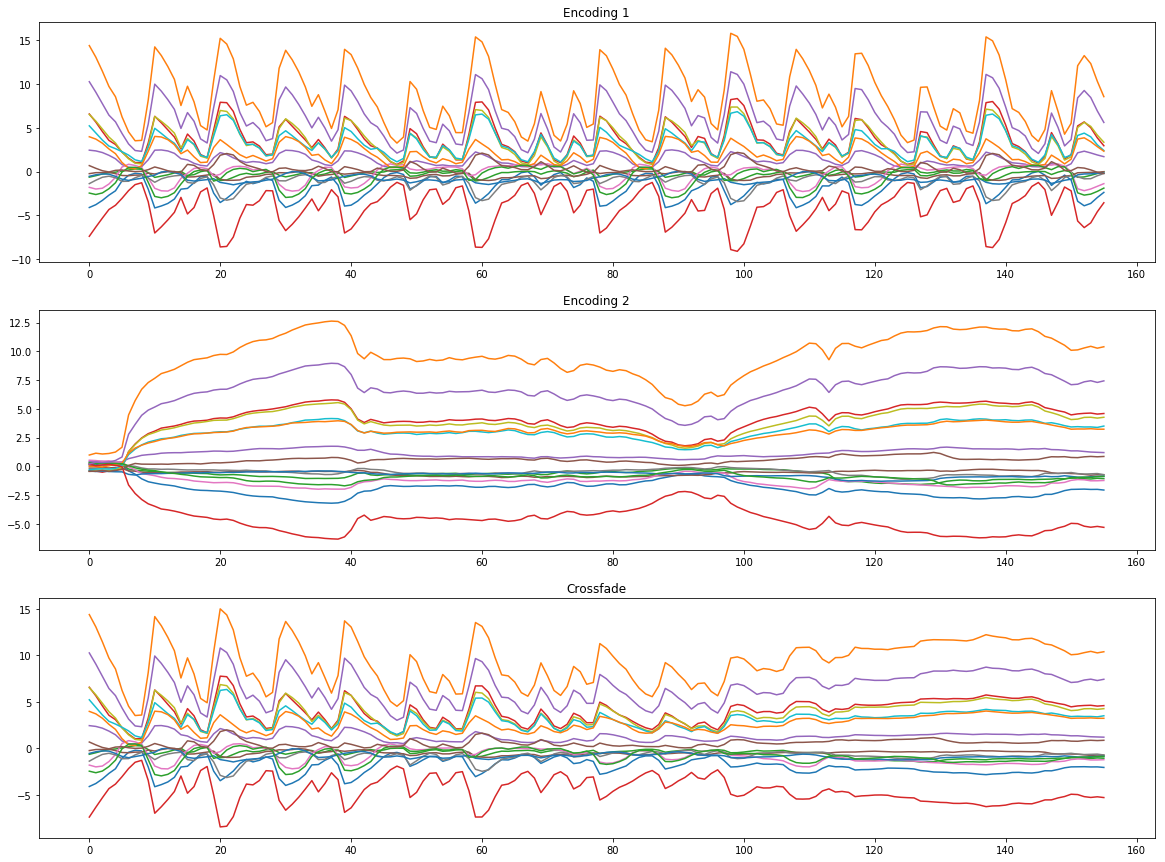
Composition
NSynth produces some amazing sounds. Once you consider its possibilities inside of your normal musical practice, you can really start to explore much more. For me I was interested in exploring composition so I tried putting some of the generated sounds together in a sort of dub-like composition inside Ableton Live. Here I was really able to explore the kinks and peculiarities of NSynth’s synthesis method and add things like delay and reverb to accentuate them. The result uses only the samples I’ve shown you so far without very much additional post-processing:
I also showed the generated sounds to a musician friend, Jordan Hochenbaum. He got pretty excited about the timestretched breakbeat synthesis and decided to use it as the foundation of a hip-hop track. The rest of the material mostly came from the string synthesis sample. He also resampled some of the generated sounds using Live’s Sampler instrument to make a bass and other polyphonic string sounds. Here’s what he came up with:
His composition really demonstrates how well NSynth can be used alongside more typical elements of a musical practice. If you are interested in learning more about sound production in Ableton Live, definitely check out his free Kadenze course on Sound Production.
Conclusion
There is a lot to explore with NSynth. So far I’ve just shown you a taste of what’s possible when you are able to generate your own sounds. I expect the generation process will soon get much faster, especially with help from the community, and for more unexpected and interesting applications to emerge. Please keep in touch with whatever you end up creating, either personally via twitter, in our Creative Applications of Deep Learning community on Kadenze, or the Magenta Google Group.