Update (9/20/18): Try out the new JavaScript implementation!
Update (10/30/18): Read about improvements and a new dataset in The MAESTRO Dataset and Wave2Midi2Wave!
Onsets and Frames is our new model for automatic polyphonic piano music transcription. Using this model, we can convert raw recordings of solo piano performances into MIDI.
For example, have you ever made a recording of yourself improvising at the piano and later wanted to know exactly what you played? This model can automatically transcribe that piano recording into a MIDI pianoroll that could be used to play the same music on a synthesizer or as a starting point for sheet music. Automatic transcription opens up many new possibilities for analyzing music that isn’t readily available in notated form and for creating much larger training datasets for generative models.
We’re able to achieve a new state of the art by using CNNs and LSTMs to predict pitch onset events and then using those predictions to condition framewise pitch predictions.
You can try out our model with your own piano recordings in your browser by visiting Piano Scribe or the Onsets and Frames Colab Notebook. We’ve also made the source code available on GitHub for both Python and JavaScript. More technical details are available in our paper on arXiv: Onsets and Frames: Dual-Objective Piano Transcription.
| Model | Transcription F1 score (0–100) |
| Previous State of the Art | 23.14 |
| Onsets and Frames | 50.22 |
More metrics and details available in our paper.
Example transcriptions:
| Input Audio | |
| Transcription |
| Input Audio | |
| Transcription |
The examples above are a good illustration of the performance of our system. There are definitely some mistakes, but it does a good job in terms of capturing harmony, melody and even rhythm.
The reason our model works as well as it does is because we split the task of note detection across two stacks of neural networks: one stack is trained to detect only onset frames (the first few frames of every note) and one stack is trained to detect every frame where a note is active. Previous models used only a single stack, but we found that by separating out the onset detection task we were able to achieve much higher accuracy.
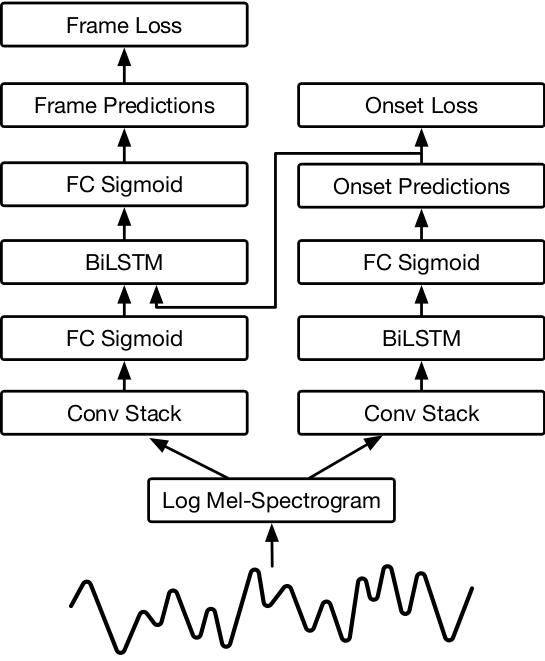
We use the output from the onset detector in two ways: we feed the raw output of that detector into the frame detector as an additional input, and we also restrict the final output of the model to start new notes only when the onset detector is confident that a note onset is in that frame.
Our loss function is the sum of two cross-entropy losses: one from the onset side and one from the frame side. Within the frame-based loss term, we apply a weighting to encourage accuracy at the start of the note. Because the weight vector assigns higher weights to the early frames of notes, the model is incentivized to predict the beginnings of notes accurately, thus preserving the most important musical events of the piece.
The figure below illustrates the importance of restricting model output based on the onset detector. The first image shows the results from the frame and onset detectors. There are several examples of notes that either last for only a few frames or that reactivate briefly after being active for a while. The second image shows the frame results after being restricted by the onset detector. Most of the notes that were active for only a few frames did not have a corresponding onset detection and were removed. Cases where a note briefly reactivated after being active for a while were also removed because a second onset for that note was not detected.
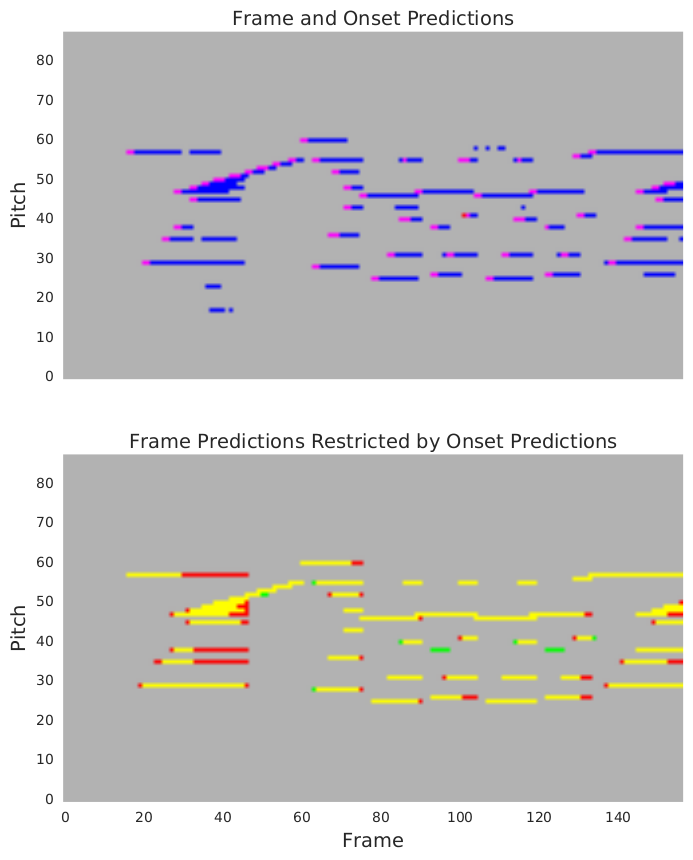
In the first image, blue indicates frame prediction, red indicates onset prediction, and magenta indicates frame and onset prediction overlap. There is only a little bit of red in the image (one note in the center), which means that most cases where the onset detector thinks there is a note, the frame detector agrees. However, there are several cases where the frame detector thinks there is a note and the onset detector does not (notes that do not have a magenta block at the beginning). Most of those frame detections are incorrect, which illustrates how important it is to remove notes that do not have a detected onset.
The second image shows the predictions after removing notes that did not have a detected onset. Yellow indicates frame prediction and ground truth overlap, green indicates an erroneous frame prediction, and red indicates ground truth without a frame prediction.
The current quality of the model’s output is on the cusp of enabling downstream applications such as music information retrieval and automatic music generation. We’re working on improvements that we hope will make the model even more accurate and useful.
We’d love to hear about your experience with this model on the magenta-discuss list. Was there a transcription that produced particularly interesting results (good or bad)? Try it out by visiting the Onsets and Frames Colab Notebook or using the code on GitHub, and let us know!
Example transcriptions are a derivative of the MAPS Database and are licensed under CC BY-NC-SA 4.0.